许淞源,刘峰
1.中国科学院计算机网络信息中心,北京 100083
2.中国科学院大学,北京 100049
随着大数据时代的到来,国家级科学数据共享服务平台建设快速发展,我国在地球科学、农业、林业、海洋、气象等领域陆续建立了一批具有资源优势的科学数据中心[1]。截至2019年6月,我国已经建立了20 个国家级科学数据中心[2]。科学数据作为大数据时代科学发现的新引擎,为科学发展进步带来新机遇与新挑战。
随着地球科学领域观测技术与数据共享平台的不断发展,越来越多有价值的科学观测数据被记录和共享,使得地球科学数据共享平台的数据量呈现爆发式增长的趋势[3],以中国科学院“地球大数据工程”数据共享服务平台(CASEarth)为例[4],目前,平台数据总量已达14PB。随着数据资源的不断增长,搜索、过滤筛选等主动检索方法虽然可以帮助用户获取目标数据[5],但其存在的服务效率低、用户体验差的缺陷也十分突出。随着大数据与深度学习技术的发展,推荐技术逐渐成熟,它通过各种算法或模型来捕捉用户的兴趣偏好,预测用户可能会感兴趣的内容[6]。目前,在电子商务平台、视频平台、新闻资讯平台、社交平台等各种领域的平台中,推荐系统获得了广泛的应用,已经成为一种提高用户获取信息效率的重要技术[7]。然而,目前关于科学数据推荐的研究还比较少。在地球科学数据共享平台的建设中,推荐技术的应用也不如在新闻、商品、视频和音乐等领域的应用成熟。
因此,本文面向CASEarth 平台,结合现有的实验数据与应用场景,设计一种地球科学数据推荐模型,帮助用户更加高效地获取地球科学数据。
1.1 基于深度学习的推荐技术
深度学习在面对海量数据时,能够从多种维度中学习符合用户需求的特征,由于其在特征表示上的优势[8],因此有越来越多的研究将深度学习应用于推荐系统中。在基于深度学习的推荐中,模型的输入通常为用户、项目相关的数据以及各类辅助数据,然后利用深度学习模型学习用户的特征表示和项目的特征表示,在输出层利用内积、相似度计算等技术对用户和项目的特征表示进行计算并生成推荐结果。基于深度学习的推荐系统框架如图1所示。

图1 基于深度学习的推荐系统框架Fig.1 Framework diagram of recommendation system based on deep learning
1.2 科学数据领域的推荐系统
在科学数据推荐领域,现有研究除了利用到传统推荐技术和基于深度学习的推荐技术,还利用了科学数据的元数据属性来挖掘数据之间的关联。例如,梁鸣霄[9]等人通过提取元数据的特征对数据进行特征表示,构建了基于内容的推荐方法,并根据用户反馈信息对用户的研究领域进行分类,将两种方法混合应用于长三角科学数据中心平台。Xue 等人[10]面向科学水资源数据共享平台,使用内容过滤与对用户行为建模的主题模型实现了一个科学数据推荐系统。Youichi 等人[11]提出了一种科学数据元数据的关键词推荐方法,通过计算数据集元数据之间的文本相似度为数据上传者推荐相应的关键词。罗侃等人[12]提出一种极地科学数据关联方法,通过对语义信息的挖掘来构建极地科学数据关联指标的计算方法。赵红伟等人[13]对地理空间元数据之间的语义关联度计算进行研究,利用数据来源、时间特征、空间特征等元数据内容构建关联网络,为地理空间数据检索、推荐等应用提供思路。在设计科学数据推荐系统时,不仅要考虑合适的推荐算法,还要结合不同领域科学数据的特征属性来设计推荐算法。
2.1 模型总体介绍
本文面向CASEarth 平台,结合平台数据与应用场景,设计了一个地球科学数据推荐模型(Earth Science Data Recommendation Model,ESDRec),来提高用户获取目标数据的效率。首先使用元数据中的标题、简介对科学数据进行特征表示,然后利用擅长处理序列变化数据的循环神经网络对其建模,考虑到普通循环神经网络在面对长序列的训练过程中可能会出现梯度消失或梯度爆炸问题,因此本文使用双向长短时记忆网络模型来处理用户行为序列。对于序列中的不同科学数据,使用注意力机制为其赋予不同的重要程度,从而进一步优化推荐模型。
对于地球科学数据而言,数据所属的学科领域、数据记录的开始与结束时间是重要的元数据属性,也是用户选择数据的重要参考属性。因此,为了设计出更加符合平台应用场景的推荐系统,进一步提高推荐准确性,本文设计了地球科学元数据特征属性关联度的计算方法,并将其计算结果加权融合到整体推荐模型中。最终,根据总体推荐预测评分的大小选取前N项科学数据推荐给用户。本文提出的地球科学数据推荐模型ESDRec 的总体结构如图2所示。
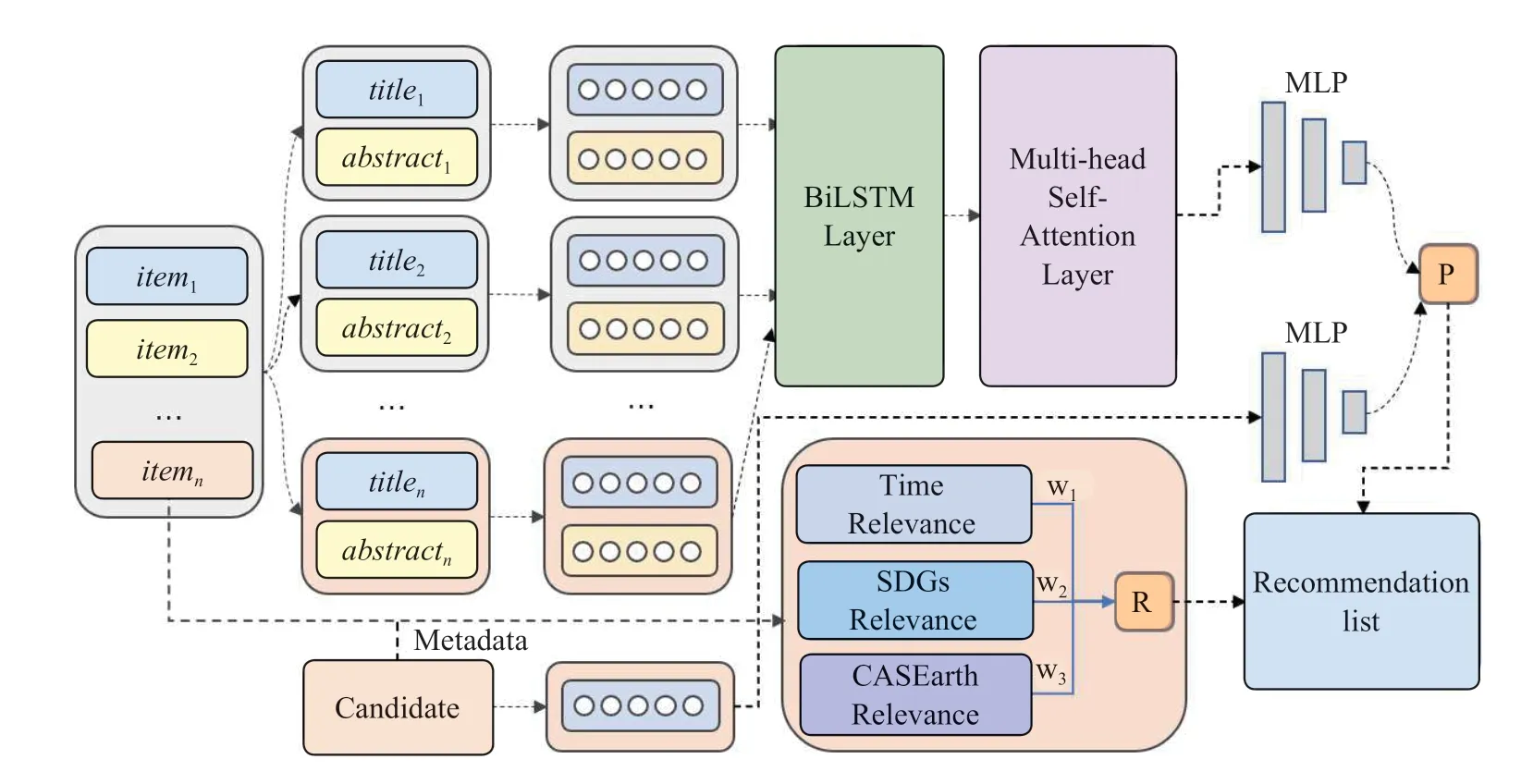
图2 地球科学数据推荐模型框架图Fig.2 The framework of earth science data recommendation model
2.2 科学数据特征表示
在对用户历史行为进行建模之前,首先要对历史行为中的科学数据进行特征表示。在这里,本文主要使用科学数据的标题与简介来构造科学数据的特征表示,对于一名用户来说,其历史行为序列可表示为其中表示某一条科学数据,并把看作是用户正在访问的科学数据。对所有科学数据的标题与简介进行分词、去除停用词等操作,然后使用Word2Vec 对用户历史访问序列中的标题与简介中的单词进行嵌入表示,得到单词的嵌入向量,然后对文本包含的所有单词向量求和,得到文本向量表示。同时,模型还要记录科学数据的元数据中的时间范围、学科分类体系,用于计算地球科学数据元数据特征属性关联度。
2.3 行为序列建模
相比于一般的神经网络,循环神经网络能够更好地处理序列数据,但是在面对长序列问题时,普通的循环神经网络存在着梯度消失与梯度爆炸的问题。长短期记忆(Long-Short-Term Memory,LSTM)网络属于循环神经网络的改进[14],其保留了循环神经网络的基本结构,并添加了门控机制来记住和遗忘过去的信息,缓解循环神经网络的梯度消失问题。单层LSTM 在对序列进行建模时,只考虑了单向序列特征。考虑到在用户历史行为序列中,某一时刻的访问会受到之前的状态影响,还可能与之后访问的科学数据有所联系,因此本文使用双向LSTM网络对用户访问序列建模。双向LSTM 将两个单向LSTM 网络叠加在一起,分别称作前向LSTM与后向LSTM,将各自的输出结果结合到一起构成BiLSTM 输出结果。在前向层中正向计算得到隐层状态,在反向层中逆向计算得到隐层状态。将两个隐层状态进行拼接得到BiLSTM 输出。
考虑到序列中不同的科学数据对用户的兴趣偏好表示也会存在不同的影响,本文将自注意力机制应用到序列推荐模型中,使得模型在训练时将注意力更多放在序列中重要的科学数据上,多头自注意力机制可以用下面公式表示
为了挖掘序列内部的相互依赖关系,使用多头自注意力机制,此处,有并且等于双向LSTM 网络模型的输出序列。为了避免梯度过小甚至消失的问题,使用缩放点积注意力计算公式,将与的点积结果进行缩放处理:
在经过Concat 层与线性映射层之后,多头自注意力网络的输出如下公式所示:
为了增强模型的拟合能力,本文在网络中加入多个隐藏层对注意力网络的输出与候选科学数据的特征表示进行处理,将多个全连接层堆叠在一起,每一层的输出都是下一层的输入,直到生成最后的输出。公式表示为:
模型采用Softmax Loss 损失函数,通过交叉熵衡量预测分布与真实分布之间的距离计算损失,并使用Adam 算法对模型进行梯度更新,损失函数的公式表示如下:
2.4 元数据特征属性关联度计算
在地球科学数据的元数据中,还可以使用科学数据的时间范围、分类体系来计算科学数据之间的关联度。本文希望通过此方法提升研究领域相同、数据记录时间相近的科学数据在推荐结果列表中的权重。
(1)科学数据时间关联度计算
科学数据元数据中包含科学数据记录的开始时间与结束时间,描绘了数据所涵盖的时间范围,对用户选择科学数据具有一定的参考意义。因此本文设计了科学数据时间关联度的计算方法。
CASEarth 平台提供的科学数据开始时间与结束时间均为年/月/日的格式,科学数据时间关联度计算方法将以天作为基本单位,把开始时间与结束时间映射到同一时间轴上,考虑到两个科学数据在时间轴上的位置关系,可以将计算方法分为以下两种情况:时间相交与时间相离。
时间相交指的是两个科学数据的数据记录时间范围在时间轴上存在重叠区域;
时间相离指的是两个科学数据的数据记录时间范围在时间轴上互不相交。特殊的,若存在一条科学数据的结束时间等于另一条科学数据的开始时间这一情况,也将其定义为相离的范畴。
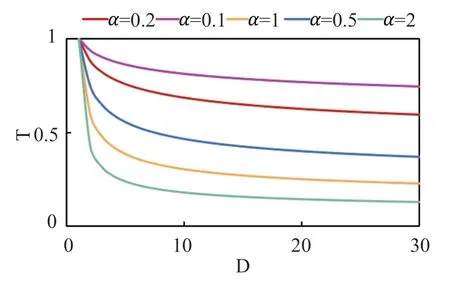
图3 科学数据时间关联度随值的变化图Fig.3 Graph of time relevance of scientifci data as a function ofvalue
(2)科学数据分类体系关联度计算
在CASEarth 平台中,地球科学数据存在两个分类体系,分别是SDGs 分类体系与地球大数据分类体系。SDGs 分类体系是联合国从社会、环境和经济三个方面制定的全球性可持续发展目标,可以为科学数据的分类提供参考。地球大数据分类体系从学科角度进行设计,以圈层结构为核心,遵循数据分类扁平化的设计思想,并结合了平台的实际需求与应用场景。本文利用的SDGs 分类体系与地球大数据分类体系的部分一级类与二级类如图4所示。

图4 SDGs 分类体系与地球大数据分类体系Fig.4 SDGs classification system and big earth data classification system
比如地球大数据分类体系中的“大气”为一个一级类,包含温度、降水、气压等二级分类[15]。当两个科学数据属于相同的一级类或二级类时,可以认为这两个科学数据具有一定的关联性。因此,本文设计了一种科学数据分类体系关联度计算方法,根据两个科学数据在分类体系中的位置关系来计算科学数据的分类体系关联度,计算方法如下式所示:
2.5 推荐预测评分融合
最后,将地球科学数据推荐模型生成的预测评分与科学数据时间关联度、科学数据分类体系关联度进行加权融合,得出最终的推荐预测分数,计算公式如下:
3.1 实验数据
本文实验基于CASEarth 平台提供的数据开展,平台的原始数据记录了自2018年12月以来所有历史访问记录约56 万条。其中包含大量冗余数据与无用数据,需对其进行过滤以增强训练数据的真实性与合理性。由于在采集用户行为数据时,平台在较短的时间间隔内会进行重复采集,因此数据集中存在大量冗余行为记录数据,根据用户进行分组,过滤掉5 分钟内同一科学数据的访问记录以提高数据集的真实性,并将访问序列长度小于等于2 的用户从数据集中过滤掉,最终剩下约7 万条历史行为记录,按照历史记录中的时间戳对用户访问序列进行排序,构建用户的项目序列。
3.2 实验设置
本文实验在模型训练过程中,将学习率设置为0.001,将迭代周期epoch 最大设置为20 次,使用Adam 优化器调整权重,利用交叉熵函数计算损失,将多头注意力机制的头个数设置为4 个。
为了验证本文提出的推荐模型有效性,本文选择以下四个推荐模型进行对比实验:
(1)item-CF[16]:这是基于科学数据之间相似度的协同过滤推荐模型。该方法不考虑科学数据在访问序列中出现的位置,仅根据当前科学数据访问列表的相似性来预测用户感兴趣的科学数据。
(2)FPMC[17]:该方法是基于马尔可夫链的序列推荐模型,能够学习序列中短期的依赖关系。
(3)SASRec[18]:该方法基于自注意力机制实现序列推荐,采用自注意力机制对用户的历史行为数据进行建模,得到用户嵌入特征向量,并与项目嵌入特征向量做内积,按照相关性大小排序生成推荐结果。
(4)GRU4rec[19]:该方法是一种由GRU 单元组成的深度RNN 网络模型,模型利用科学数据序列上下文以及序列顺序进行训练,输出对下一个候选科学数据进行排名的得分向量。
3.3 评价指标
本文实验采用召回率(Recall@N)与平均倒数排名(MRR@N)来检验ESDRec 模型的有效性。下面的公式给出了两个评价指标的计算方法,二者的值越高则表示推荐模型的实验结果越好。
Recall@N:召回率定义为用户真实交互序列的下一个项目出现在Top-N 推荐列表中的比例,即推荐系统给用户推荐项目中用户喜欢的项目所占比例。
MRR@N:平均倒数排名(Mean Reciprocal Rank)测量所有测试数据上真实目标项目的预测位置的平均倒数排名,第一个正确预测结果越靠前,则MRR@N 的值越高。
3.4 实验结果与分析
将本文提出的推荐模型ESDRec 与其他基线模型进行对比实验,实验结果如图5和图6所示。

图5 在Recall@N 上的对比实验结果Fig.5 Comparative experimental results on Recall@N

图6 在MRR@N 上的对比实验结果Fig.6 Comparative experimental results on MRR@N
在五个方法的对比实验中,可以发现本文提出的模型在召回率与平均倒数排名上均取得了效果的提升。在其他四个基线模型中,SASRec 在召回率和平均倒数排名上取得了较好的效果。
对于Recall@N 评价指标来说,ESDRec 在N 小于12 时的提升较大,在N=10 时,与最佳基线模型SASRec 相比,提升了5.01%。随着N 的不断增大,召回率与其他基线模型的差距逐渐减小。
对于MRR@N 评价指标,ESDRec 在各个N上的表现也均好于其他基线模型。其主要原因是ESDRec 模型使用了双向LSTM 网络来学习序列中的上下文依赖信息,充分挖掘了用户行为序列中前向与后向的依赖关系,然后利用多头注意力机制来区分序列中每个科学数据的重要程度,在一定程度上减少了用户序列中存在的噪声,使得本文模型能够更好地捕捉预测目标数据与序列上下文之间细化的关联。另一方面,ESDRec 模型引入了地球科学数据特征属性关联度的计算机制,能够帮助推荐模型找到与目标数据元数据更相似的其他科学数据。
另外,从实验结果中还可以发现基于循环神经网络的方法均优于传统的模型(Item-CF,FPMC),主要原因在于循环神经网络结构相比于传统模型更加擅长学习序列中的上下文依赖关系,从而提高了推荐效果。而且,使用了注意力机制的模型(ESDRec,SASRec)在召回率和平均倒数排名上的表现更好,主要原因在于注意力机制能够帮助推荐模型发现对预测结果影响更大的科学数据,让模型更专注于找到输入数据中显著的与当前输出相关的有用信息,从而提高输出的质量。
其次,为了验证地球科学数据特征属性关联度计算模块对本文推荐模型效果的影响程度,本文设置了一组对照实验,在地球科学数据推荐模型中去除科学数据元数据特征属性关联度的计算,与ESDRec 模型进行对比实验,对比实验结果如图7和图8所示。

图7 在Recall@N 上的对比实验结果Fig.7 Comparative experimental results on Recall@N

图8 在MRR@N 上的对比实验结果Fig.8 Comparative experimental results on MRR@N
若不使用元数据特征属性关联度的计算方法,推荐模型的MRR@N 与Recall@N 指标均存在一定程度的下降。其中,召回率指标略有下降。而MRR@N 指标在不使用元数据特征属性关联度计算时结果的下降较大,主要原因是推荐模型引入元数据特征属性关联度计算后,能够较好地提升元数据特征相似的科学数据在推荐列表中的排名,进而提高了MRR@N 的结果。
本文面向CASEarth 平台,提出了一个地球科学数据推荐模型ESDRec,来帮助用户更高效地获取科学数据。模型利用双向长短时记忆网络学习用户的行为序列,结合多头注意力机制识别序列中的关键信息,降低行为序列中的噪声对推荐结果的影响,生成用户偏好向量与候选集中科学数据计算推荐预测评分,并融合地球科学数据特征属性关联度对推荐结果进行综合排序,将预测分数较高的科学数据作为推荐结果。在CASEarth 平台真实数据集上的对比实验结果表明本文提出的ESDRec 模型能够准确地生成推荐结果。
利益冲突说明
所有作者声明不存在利益冲突关系。
猜你喜欢关联度科学特征根据方程特征选解法中学生数理化·中考版(2022年9期)2022-10-25如何表达“特征”疯狂英语·新策略(2019年10期)2019-12-13点击科学中国科技教育(2019年12期)2019-09-23科学大爆炸小小艺术家(2019年6期)2019-06-24不忠诚的四个特征当代陕西(2019年10期)2019-06-03中国制造业产业关联度分析智富时代(2019年2期)2019-04-18中国制造业产业关联度分析智富时代(2019年2期)2019-04-18抓住特征巧观察数学小灵通·3-4年级(2017年9期)2017-10-13基于灰关联度的锂电池组SOH评价方法研究电源技术(2015年11期)2015-08-22科学拔牙小雪花·成长指南(2015年3期)2015-05-04


